🔎
Real-time Object Detector
using computer vision
What
A real-time object detection system that identifies 80+ object classes through your webcam using YOLOv8. Point your camera at anything
People, vehicles, animals, everyday objects, etc.
and watch it draw bounding boxes with confidence scores in real-time.
Built to understand how modern object detection works from the ground up. I concluded that if YOLO can process 640×640 images at 30+ FPS while running convolutional neural networks with millions of parameters, computer vision has come a long way from the hand-crafted feature detectors of the past.
But perhaps what struck me most was how simple it felt once the pieces came together. A hundred lines of Python, a pretrained model, and suddenly you have something that sees.
You may clone the repo to try it out for yourself. And please, if you have any additional features or spot a bug, open up a pull request.
Me demoing the detector
Case Study
This was the project where all the deep learning theory (convolutions, activation functions, backpropagation, gradient descent) finally manifested into something tangible. After building this, I'm convinced that computer vision is where I want to spend more time.
It was also refreshingly different from web development. No APIs to design, no state management headaches, no deployment pipelines.
Just: write code, point camera, see if it detects your coffee mug, iterate.
I had spent months thinking about systems in terms of requests and responses, databases and authentication, frontend and backend. But computer vision operates in a different paradigm entirely. Here, the system sees. And that felt fundamentally different.
Context
This started as a "cheat project" while taking a break from web development. I wanted something quick and visual that would let me explore computer vision without committing to a massive research project.
YOLO (You Only Look Once) seemed like the obvious choice. It's not only fast and accurate, the pretrained models can handle 80 object classes out of the box. So I spun up a Python environment and got to work.
But let me be clear about something. I did not invent YOLO, nor did I train these models from scratch.
Joseph Redmon and his team did that work (arXiv paper 🔗) in 2016, fundamentally changing how we approach real-time object detection. What I built was an implementation: a way to understand the system by using it, extending it, and watching it work.
Approach
Webcam capture via cv2.VideoCapture, YOLOv8 from Ultralytics for detection, and OpenCV for all rendering. The architecture is straightforward:
capture frame → run through YOLO → draw bounding boxes → repeat
Each detection gives you a bounding box \( (x, y, width, height) \), a confidence score, and a class label. The confidence threshold filters out weak detections: set it too low and you get false positives, too high and you miss legitimate objects.
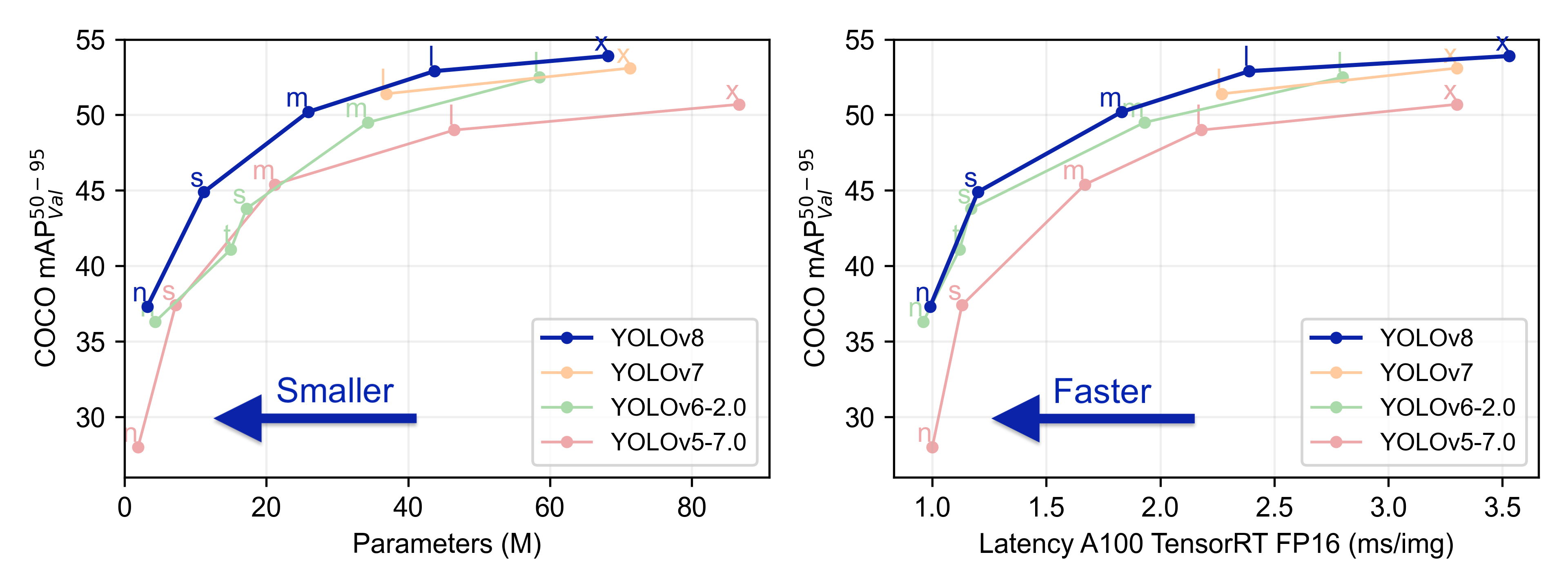
I added basic features like frame capture (press "c" to save), FPS counter, and the ability to switch between different YOLO model sizes (nano for speed, xlarge for accuracy).
The main game state is minimal:
- current frame from webcam
- detection results (list of boxes, confidences, classes)
- model parameters (size, confidence threshold)
- frame counter
Each frame gets preprocessed (resized to 640×640, normalized), fed through the neural network, then post-processed with Non-Maximum Suppression (NMS) 🔗 to eliminate duplicate detections of the same object.
The Math
When you break this down, layer by layer, the majority is just math. It's like a crash course in deep learning math: convolutional operations, feature extraction, bounding box regression, and probabilistic classification.
Perhaps the elegance of YOLO lies in its simplicity. Where earlier methods like R-CNN 🔗 required multiple passes and complex region proposals, YOLO looks once, hence the name, and makes all predictions simultaneously.
That single insight changed everything.
YOLO divides each input image into an \( S \times S \) grid. Each grid cell predicts \( B \) bounding boxes and confidence scores. The confidence represents:
\( \text{Confidence} = P(\text{object}) \times \text{IoU}_{\text{pred}}^{\text{truth}} \)
Each bounding box consists of 5 predictions: \( (x, y, w, h, \text{confidence}) \) where:
- \( x, y \) are the center coordinates relative to grid cell bounds
- \( w, h \) are width and height relative to the whole image
- \( \text{confidence} \) is the objectness score
The actual bounding box coordinates are computed using anchor boxes and sigmoid activations:
- \( b_x = \sigma(t_x) + c_x \)
- \( b_y = \sigma(t_y) + c_y \)
- \( b_w = p_w \times e^{t_w} \)
- \( b_h = p_h \times e^{t_h} \)
where \( \sigma \) is the sigmoid function, \( (c_x, c_y) \) is the grid cell location, and \( (p_w, p_h) \) are the anchor dimensions.
Now for Intersection over Union (IoU), which measures how much two boxes overlap:
\( \text{IoU} = \frac{\text{Area of Overlap}}{\text{Area of Union}} = \frac{A \cap B}{A \cup B} \)
This is critical for NMS, which eliminates redundant detections. NMS works by:
- sorting all boxes by confidence score
- keeping the highest confidence box
- removing all boxes with \( \text{IoU} > \text{threshold} \) with the kept box
- repeating for remaining boxes
The loss function during training is multi-part, combining classification loss, localization loss, and objectness loss:
\( \mathcal{L}_{\text{total}} = \lambda_{\text{cls}} \mathcal{L}_{\text{cls}} + \lambda_{\text{box}} \mathcal{L}_{\text{box}} + \lambda_{\text{obj}} \mathcal{L}_{\text{obj}} \)
Where the box loss uses Complete IoU (known as CIoU):
\( \mathcal{L}_{\text{CIoU}} = 1 - \text{IoU} + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v \)
💡 For reference:
(1) \( \rho =\) distance between predicted and ground truth box centers
(2) \( c =\) the diagonal of the smallest enclosing box
(3) \( v \) measures aspect ratio consistency
At the core, convolutions extract features by sliding kernels across the image:
\( \text{Output}(i,j) = \sum_m \sum_n \text{Input}(i+m, j+n) \times \text{Kernel}(m,n) \)
These features get processed through multiple layers with Rectified Linear Unit (ReLU) activations:
💡 ReLU is defined as \( f(x) = max(0, x) \)
And that's the essence of it.
The whole detection pipeline is essentially:
But perhaps what these equations don't capture is the historical weight behind them.
Before deep learning, computer vision relied on hand-crafted features (ex: SIFT, HOG, Haar cascades). Basically just methods that required human experts to manually design what the algorithm should look for. It worked, but it was brittle.
YOLO, and CNNs in general, changed that.
The features are learned, not designed. The network discovers what matters through backpropagation and gradient descent . And that shift from hand-crafted to learned representations is what made modern computer vision possible.
Outcome
This project shifted my perspective on what's possible with relatively simple code. A hundred lines of Python and suddenly you have a system that can identify objects in real-time with startling accuracy.
The math is dense: CNNs, loss functions, gradient descent, etc., but seeing it work in practice made everything click. There's something deeply satisfying about pointing your webcam at a random object and watching the model be able label it.
I felt like a proud dad and this script was my kid labeling that I was actually a person.
Now I have a working object detection framework that I can extend. Maybe add object tracking across frames, or train it on custom classes, or build a zone-based alert system.
I tell you this not because I've mastered computer vision, but because I've seen enough to know that this is where I want to go deeper. The boundary between software that processes information and software that perceives the world is narrowing. And I want to be part of that.
Future prospects: possibly fine-tuning YOLO on custom datasets, or diving into segmentation models like SAM. Who knows. Reach out if you want to collaborate on something in this space.
Tech Stack
Core
- Python 3.8+
- Ultralytics
YOLOv8(state-of-the-art object detection) - OpenCV (video processing and rendering)
- PyTorch (deep learning backend)
ML Model
- YOLOv8 (pretrained on COCO dataset)
- 80 object classes
- Multiple model sizes (nano to xlarge)
Platform
- Cross-platform (macOS, Windows, Linux)
- Webcam-based input
- Real-time inference (30+ FPS)